리액트 쿼리는 왜 쓸까?
2023/01/29
n°30
category : react-query
☼
2023/01/29
n°30
category : react-query

프로덕션에서 리액트 쿼리 도입을 앞두고 있고, 개인적으로도 관심이 많아서 정리 해본다. 저에겐 아직 낯설고, 부족한 부분이 많으니 이상한 부분이 있으면 꼭 방명록에라도 지적해주시면 감사하겠습니다.
-
리액트 쿼리에 관심을 갖게된 계기는 리액트 쿼리 공식문서에 올라온 swr과 비교하는 자료 때문이다.

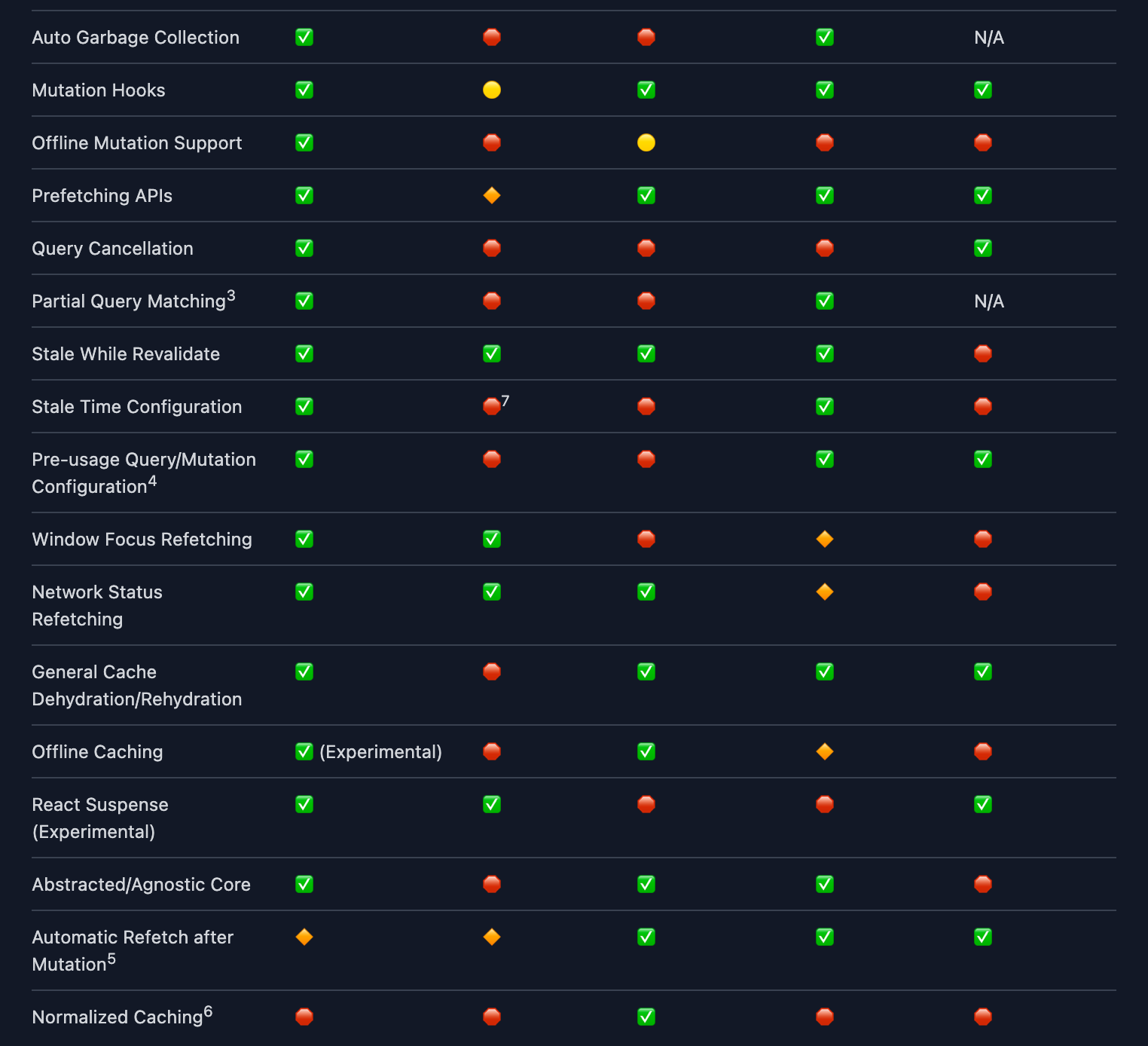
얼핏보면 swr도 캐싱할 수 있고, 겹치는 기능이 많아 유사해보인다. 하지만 query 관리, mutation, offline support, prefetch 부분은 Relay를 떠올리는 구석이 많기 때문에 관심이 갈 수 밖에 없었다. (릴레이 사랑합니다..) 쿼리 관리하는 부분만 보더라도, 리액트 쿼리가 훨씬 섬세하단 걸 알 수 있다. 학습 난이도가 있겠지만, 능숙해진다면 최적화의 끝을 볼 수 있겠다.
간단히 말하자면 데이터 상태관리 툴이다. 비동기 요청으로 가져오는 데이터(의 상태)를 관리하기 위한 라이브러리. 공식문서의 overview 항목은 라이브러리의 필요성을 잘 설명해준다. 이하는 공식문서 인용
-
전통적인 상태 관리 라이브러리는 클라이언트 상태를 처리하는 데에 좋지만, 비동기 또는 서버 상태를 처리하는 데에는 적합하지 않습니다. 이는 서버 상태가 완전히 다르기 때문입니다.
첫 번째로, 서버 상태는:
응용 프로그램에서 서버 상태의 성격을 이해하면, 추가적인 문제가 생깁니다. 예를 들어:
react-query는 이러한 서버 상태를 처리하는데 특화되어 있고, 이러한 문제들을 해결하는데 도움을 줄 수 있습니다. 이를 비교할 경우, SWR은 주로 브라우저 캐싱을 통해 클라이언트 상태를 관리하는데 초점을 맞추고 있지만, react-query는 서버 상태를 관리하는데 초점을 맞추고 있습니다. 따라서, 서버 상태를 처리하는데 초점을 맞추어야 하는 경우 react-query가 더 적합할 수 있습니다.
비동기 처리에 대한 문제 정의와 라이브러리가 필요한 이유를 깊이 있고 명쾌하게 설명해주고 있다. 서버 상태에 초점을 맞춘다는 점이 인상깊다.
두 라이브러리 모두 사용하고 느낀점. swr은 자동으로 해주는 부분이 많아서 편하다. 편하기 때문에 깊게 알 필요가 없을 때가 많다. 즉 손가는 대로 사용하기 쉽다. 반면 리액트 쿼리는 직접 손 댈 여지가 많다. 물론 마찬가지로 생각없이 사용하기 편하나, 더 나은 방식이 아닐 가능성이 크다. 다만 제대로 알고 사용하기까지 swr보다 난이도가 좀 있는 편인 것 같다.
그리고 캐싱을 제어하는 옵션, 메소드들이 상당히 많다. 성능 최적화에 핵심이 될 수 있겠다고 얘기한 이유는 그 때문이다. 리액트 쿼리를 사용하다 보면 캐싱의 중요성을 느낄 수 밖에 없게 된다.
쿼리 클라이언트는 "캐시와 상호작용하기 위해 사용한다". 개인적으로 queryClient의 캐싱이 리액트 쿼리의 근간처럼 느껴졌다. 쿼리 클라이언트를 사용하기 위해선, QueryClientProvider로 쿼리가 사용될 컴포넌트를 감싸주어야한다. 아래 예시는 블로그 방명록에 사용한 코드.
<QueryClientProvider client={queryClient}>
<GuestbookTemplate />
</QueryClientProvider>
쿼리 클라이언트는 수 많은 프로퍼티를 갖고 있으니, 각 프로퍼티에 대한 설명은 공식문서를 참조. 다만 서버와 통신하여 데이터를 업데이트하는 것(Mutation)과 연관된 메소드는 알 필요가 있을 것 같다.
const mutationCache = queryClient.getMutationCache()
클라이언트에 연결된 mutation 캐시를 반환하는 메소드이다.
await queryClient.invalidateQueries({
queryKey: ['posts'],
exact,
refetchType: 'active',
}, { throwOnError, cancelRefetch })
"invalidateQueries 메소드를 사용하여 쿼리 키 또는 쿼리의 다른 기능적으로 액세스 가능한 속성/상태를 기반으로 캐시에서 단일 또는 여러 쿼리를 비활성화하고 다시 가져올 수 있습니다. 기본적으로 일치하는 모든 쿼리는 즉시 잘못된 것(invalid)으로 표시되고 활성화된 쿼리는 백그라운드에서 다시 fetch됩니다."
중요하기 때문에 공식문서에도 특별히 길게 설명되어있다. 그럼에도 약간 난해하게 느껴진다. 쉽게 이해하자면, 주로 서버에 데이터 변경 요청을 보낸 후, 새로운 데이터를 반환받기 위해 사용된다. useQuery의 refetch와 비슷하지만 다르다. "refetch() 는 데이터의 stale 함과 상관 없이 & 쿼리에 대한 observer 가 없더라도 항상 refetch 하지만, invalidateQueries 는 기존 데이터를 stale 로 변경 후 마운트되어야 refetch 가 동작한다고 한다." (출처) 즉 쿼리의 상태를 어떻게 관리할 것인가-의 차이가 있다. 이런 부분에서 상당히 섬세하다고 느껴진다. 여러 optional args가 있기 때문에 역시 참조할 필요가 있다.
queryClient.clear()
쿼리 클라이언트에 연결된 모든 캐시를 비운다.
가장 기본적인 데이터 요청 훅이다. swr의 useSwr 훅과 비슷한 역할. 하지만 캐시 관련 설정이나, refetch 조건을 설정해줄 수 있다는 점이 swr과 큰 차이인 것 같다. 훅 내부에 config처럼 넣는 옵션 중 쓸만한 것이 많다. 중요한 훅이라서 returns, options가 많다. 마찬가지로 다 외울 필요없지만, 중요한 부분은 꼭 알아야한다.
Returns
서버와 통신 후 resolve된 데이터이다. undefined가 기본값.
서버와의 통신 상태를 나타내는 문자열 반환값. 'loading', 'error', 'success' 세가지 문자열이 될 수 있다. isLoading, isError 같은 boolean 타입의 반환값들도 있어 중복되는 느낌이 없잖아 있다.
캐시에서 쿼리를 삭제하는 메소드이다.
중요하다. 수동으로 쿼리를 refetch하는 메소드이다. 주로 useMutation을 이용해 데이터를 업데이트 시킨 후, 새로운 데이터를 받아오기 위해 사용한다. args로 들어가는 옵션 중 throwOnError:true 일 경우, refetch에서 에러 발생 시 error를 throw한다. cancelRefetch의 default는 true이다. true일 때 기본적으로 현재 실행 중인 요청은 새 요청이 만들어지기 전에 취소된다. false로 설정하면 이미 실행 중인 요청이 있는 경우 refetch되지 않는다. (cancelRefetch는 어떤 경우에 사용될 지 짐작은 가나, 아직 정확히 와닿진 않는다. 과도한 refetch를 방지하기 위한 옵션으로 예상된다.)
-
returns는 심플하다. useSwr과 유사한 부분이 많다. 큰 차이점은 options에서 나타난다. 그리고 더 중요하다. 그래서 공식문서 상에도 더 자세히 설명되어있다.
Options
데이터를 요청하기 위한 함수가 들어간다. useSwr의 fetcher에 대응된다고 생각하면 이해가 쉽다. 데이터를 resolve하는 프로미스 객체 혹은 에러를 반환하는 함수여야 한다. 프로미스가 resolve하는 데이터는 undefined일 수 없다. QueryFunctionContext를 받는다.
요청의 성공(onSuccess)과 실패(onError)에 따라 실행될 함수를 넣어줄 수 있다. 주로 요청 이후, 리렌더링을 위한 useState의 setter(SetStateAction)가 들어간다. 물론 다른 액션이 들어갈 수 있겠다. 생각보다 필수적이고, 활용도가 높다.
두 설정은 중요해서 차이점을 짚어볼 필요가 있다. 두 설정 모두 요청하는 데이터의 상태가 자주 변경될 때 활용될 수 있다.
- staleTime
- cacheTime
( 이 글을 참조하여 덧붙였습니다. )
숫자로 설정하면 모든 쿼리가 이 빈도(밀리초)로 계속 refetch된다. 함수로 설정 시, 함수는 최신 데이터와 쿼리를 사용하여 빈도를 계산한다(?). refetchIntervalInBackground: true와 함께 사용될 시, 브라우저나 탭이 닫힌 상태에서도 입력한 빈도만큼 계속 refetch가 실행된다.
브라우저에 포커스 됐을 때, 쿼리 인스턴스가 mount되었을 때 등등. refetch가 일어나는 시점과 연관된 여러 설정이 있으니 참조. 이런 디테일이 대단하다. 이 외에도 suspense, initialData, placeholderData 등등 살펴볼 설정이 많다. 너무 많기에, 우선은 넘어가는 것으로..
아래는 마찬가지로 블로그 방명록에 사용한 코드이다. 무한 스크롤 때문에 useInfiniteQuery를 사용했지만, 공식문서에 나와있다 싶이 useQuery와 거의 동일하다. returns나 options에 페이지네이션과 연관된 차이들이 있다. 처음이라 이게 맞나 싶으니 피드백 환영입니다.
const {
data: queryData,
fetchNextPage,
isFetchingNextPage,
refetch,
isLoading,
error: isError,
} = useInfiniteQuery({
queryKey: ["cursor", "access_token"],
queryFn: ({ pageParam = pageCursor.current }) => {
const res = getGuestbookListFetcher(pageParam, access_token.current);
return res;
},
cacheTime: 0,
refetchOnWindowFocus: false,
onSuccess: (data) => {
if (data.pages[data.pages.length - 1].length < 20) {
setIsLast(true);
return;
}
pageCursor.current = pageCursor.current + 20;
},
});
useQuery에 대해 작성하다 보니 글 분량이 너무 길어지는 것 같아서 간략히 살펴보기로. Create, Update, Delete와 연관된 요청은 useMutation 훅을 활용한다. = 서버 데이터의 상태 변화와 연관된 요청은 이 훅을 사용한다.
useMutation({...options}) 형태이며, useQuery와 유사한 설정들이 많다. 하지만 useQuery와 요청 함수는 다를 수 밖에 없다. 그러므로 이 부분을 확실히 알아야 한다. 간략히 두가지만 살펴보자. Options의 mutationFn, Returns의 mutate
필수로 설정해주어야 한다(required). useMutation의 설정으로 들어가는 요청 함수. variables는 간단히 말해 요청 body에 들어갈 key의 value들이다. 이 형태를 지켜줘야 returns에 있는 mutate 메소드에 이 요청 함수를 넘겨줄 수 있다.
요청을 위해 useMutation을 곧바로 사용하지 않는 대신, 훅이 반환하는 mutate 함수를 사용한다. useMutation과 이름이 비슷하고, 겹치는 설정이 많아서 진짜 헷갈린다. 클라이언트에서 요청을 보낼 땐 이 함수를 호출하면 variables에는 요청 body에 들어갈 값들을 넣어준다. 그 외로, onSuccess 등등의 효과는 다른 훅들과 동일하다. useMutation 내부에 설정된 onSuccess와 mutate 내부의 설정된 onSuccess 실행 순서는 1)useMutation 2) mutate 순이다. 생각해보면 당연하지만, 모르는 부분이 있는 것 같다. 더 살펴볼 필요가 있다.
이하는 블로그 방명록의 create post 부분 코드. 참고로 useMutation훅에 첫번째 인자에 바로 요청 함수 주고, 두번째 인자로 객체와 옵션키들을 넣어 줄 수도 있다. (다른 훅 또한 마찬가지다.) 하단 예시 참조.
const { mutate } = useMutation(postGuestbookPost, {
...
onSettled: () => {
setCursorZero();
refetch();
},
});
const handleSubmit = async (e: MouseEvent) => {
e.preventDefault();
if (!post) {
alert("Post is empty");
return;
....
mutate(
{ author, post, isPrivate },
{
onSuccess: () => {
setCursorZero();
refetch();
setIsPost(false);
},
onError: (e) => {
setIsPost(false);
},
}
);
};
역시 처음이라 맞는 지 모르겠습니다. 피드백 감사하겠습니다...
글을 다 쓰고나서 보니 쿼리 인스턴스의 흐름(생애주기?)이 핵심이란 생각이 든다. 몇 번 읽어봤고, 감은 잡히니까 정리할 필요가 있다. 그걸 이해해야 인스턴스 마운트시 fetch, 캐싱 등 코어한 부분을 제대로 이해할 수 있을 것 같다. 설명을 건너뛴 부분들도 많아서, 다음엔 필요한 훅 하나에 대해 깊이 있게 살펴보는 게 낫겠다.
한가지 염려되는 점은 코드 복잡성을 높일 수 있는 점. 내 숙련도 뿐만 아니라, 팀원들이 경험이 충분치 않다면 되려 생산성 저하가 있을 수 있겠다. 불필요하게 fetcher를 매번 작성해서 인자로 넘겨준다거나, mutate와 useMutation options는 진짜 너무 헷갈린다. 잘못된 패턴으로 작성된다면 나든 우리 팀원이든 잘못된 코드를 보고 상당히 난감할 수 있겠다.
사실 나도 부족하다. 블로그 방명록을 22/12/31에 배포하려고 했는데 리액트 쿼리가 낯설어서 너무 늦어졌다. mutation 이후 쿼리의 캐시가 도통 삭제되지 않는 문제가 있었다. refetch, clientQuery.invalidateQuries, clientQuery.clear 별에 별 난리를 다 쳤는데도. 그러다가 useInfinityQueries에 들어가는 요청 함수 헤더에 "Cache-Control : no-cache"를 추가해주니 캐시 관리가 제대로 되었다. 왤까.. 역시 추측되지만 정확히는 모른다. 그냥 이런 호기심은 꼬리에 꼬리에 꼬리를 물기 때문에, 필요한 것들 위주로 나중에 다시 볼 필요가 있다. 다음엔 공식문서->블로그글->글 작성하면서 작업에 임해도 좋겠다.
긴 글 읽어주셔서 감사합니다 :)